
Is it the end for Apache Airflow?
Or more detailed version of my PyCon LT presentation

This is the extended version (though without some of the jokes I made on stage, but with some new ones!) of my presentation with more details, some dives into the code and my struggles that weren’t mentioned in the talk I gave at PyCon LT 2023. Since it’s a long post, it won’t fit into an email, so if you’re interested in what I have to say - open on substack.
When the video recording of the talk will appear I’ll add it to this post!.
I’m going to cover only Apache Airflow, Mage and Dagster.
I know that there is Kedro, Prefect, Kestra and many others out there, but when I was focusing on the talk, these three mostly appeared in my Linkedin feed, so it seemed like a fair competition. Most likely, I’ll; after some time, I’ll go over others too. Evaluating other tools’ capabilities and choosing the right tool for the job is never wrong.
So let’s start with the slide deck I’ve used. Somehow I ended up with 46 slides and 25mins of time. The topic name specifically was chosen to be clickbait to get more attraction.

First time for everything
I wasn’t nervous till the day of my presentation. I’ve tweaked/added something/moved something in my slides seven times in the morning. Thinking of different scenarios, what to talk about and how to structure each time something is not good enough until suddenly - it is what it is, has to be good enough, and will never be perfect. Jumping on the stage, arms are shaking, legs are wobbly and straight in my head plays “Lose Yourself” by Eminem, “Knees weak, arms are heavy, … moms spaghetti.” It is what it is; let’s go!
After a short intro from my inner battles and thoughts of actually not being able to speak during the presentation, I guess it’s time to talk about what I covered as well as what I didn’t manage to cover during the PyCon LT 2023 with more code (as well cleaner code, that I’m trying to do while preparing this post 😅
Intro and biases
Everyone is biased. Being an airflow user for 5-6 years, you get used to things; you tend to reach your comfort zone in specific tooling. Same with me. So when I saw this post by Zach Wilson

knowing that he’s an advisor to the mage.ai, it seemed like an even game, “you do you, I’ll do me”. Some of my acquaintances tried Dagster and were stoked about it;
So now, before even trying these tools, I’m super biased. I already have my favourite; why I’m trying to make some comparisons? My inner critic said, shut up and prepare; you can’t speak in front of an audience without proof.
The challenge
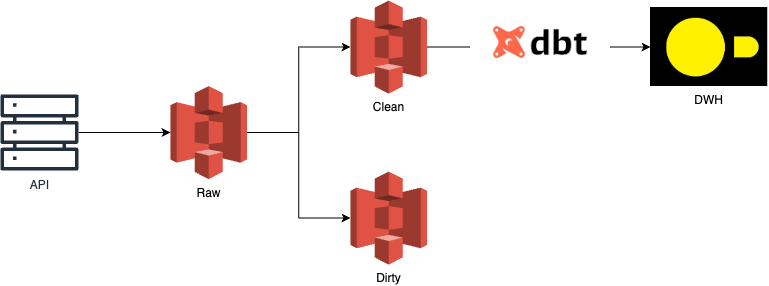
The simple schema looks like the one shown above. The orchestrators’ job is to do it all. The dataset available via HTTP request was the one and only Yellow Taxi data.
The fun thing is that now I’m losing the homework assignment that I send to candidates when hiring Data/Analytics Engineers, and this solution I’m providing is a fair enough solution for them to pass the Junior-Mid role bar (of course, more things are always better).
DWH, in this scenario, should look something like this:

Obstacles along the way
The story wouldn’t be complete if I didn’t clarify some things before going into more detail.
Choosing DuckDB for dbt transformations and running things in parallel on the same DB files wasn’t my brightest idea. DuckDB is similar to SQLite but aimed at analytics, lightweight, etc., but it’s not designed to do parallel writes since we’re locking files. Me being exactly me from the meme I created some time ago

My post from some time ago with it https://www.linkedin.com/posts/tomaspeluritis_airflow-dataengineering-data-activity-6901938900026093568-zhBV
Only to realize the hard way later after half an hour what’s causing the failures. While the conference was getting closer, I decided to do an Elon Musk - remove some things and see if it worked.
It was OK for the presentation, but I’m running seeds as a single step sequentially for all orchestrators for a more professional look and real-life scenario-wise.Macbook M1 - Started all development on M1; some libraries are not yet compatible, so using a simple workaround provides a docker-compose platform. So all things run in emulated environments. It feels a bit like inception, but it is what it is—had fun with Mage.ai, which worked like this and suddenly didn’t. Talking in Slack, they suggested dropping the platform part, which works. The fun thing is that when checking results, I noticed a massive difference between Dagster and Airflow with the amd64 platform and Mage with native—almost 2x diff. So I had to whip out my Ubuntu laptop to make it fair, and it took me a lot to figure it out.

Apache Airflow
I hated remembering dates mainly because of history lessons at school - but now dealing with timestamp formats may be the thing I hate related to dates. So there is some historical information about Airflow that I managed to stitch from different sources to raise my credibility, and I did some research about the tool 😅
Created at Airbnb in October 2014
Initial release date to public June 3, 2015
Apache incubator project in March 2016
Top-level Apache Software Foundation project in January 2019
But for me, more exciting things are: is there a commercial offering, and are there options on cloud providers?
Astronomer - Startup created by the creators (not all, but I think many of them). They’re massively driving development and contribution to Open Source.
Talking about cloud providers - each has some Airflow options:
AWS - Managed Workflows for Apache Airflow
GCP - Cloud Composer
Azure - Data Factory (being the relatively fresh addition to Microsoft Cloud)
If we’re looking at the adoption of the tool:
Slack: 31k members
Github Stars: 30.1k
Docker pulls: 113M
Downloads PyPi: 8.4M/month
To me - Github stars, Docker pulls, and Downloads are not great adoption indicators since they might be affected by some other processes (Dev env docker pulls/pip installs, CI/CD, etc.). What I honestly think can be a good measure is Slack members-related metrics. Though slack members count is not the best metric, at least I can’t get Active (sent at least a couple of messages in the platform), so members count will have to do.
Architecture
In a nutshell, Airflow architecture can be generalized.

I’m not much of an expert on things in more detailed (k8s or Celery matters), so I won’t say a thing; I do not want to embarrass myself or get nasty comments, so I will leave it as is.
Talking about some basic terms on airflow:
DAG - direct acyclic graph. Basically, the workflow you define in your code.
Task - a task to be executed. By default should be doing one thing only.
Dataset - reference defined in airflow to a file/table/etc.
Connection - information about connection to some service/database/API.
User Interface
Most of you might be familiar if you’re using it, but as boring as it may be, I’ll leave it so you can use this post as a reference.

So actually, if you’re looking carefully, you can see that the dbt_dag schedule is strange, and it’s because it’s using Dataset aware scheduling (Airflow docs). I could have created one dag, but I like to tinker with some exciting features (sometimes it backfires, as you might have read above). It doesn’t change the whole outcome; just let me here to see some benefits I’ve missed and that some other orchestrators are bragging about.
It looks like this in the UI:

You can see what dags generate or update some datasets, which dags depend on which datasets, etc.
Airflow Code
I’m trying not to be as technologically challenged as I like to say to myself, so I'm trying to use decorators. So Dag, for extracting looks

Then we have the extraction task:

And then cleaning and separating some information

There is one helper function, but you can check it out in GitHub later (link at the end).
And then dbt_dag:

Simple.
Runtimes:

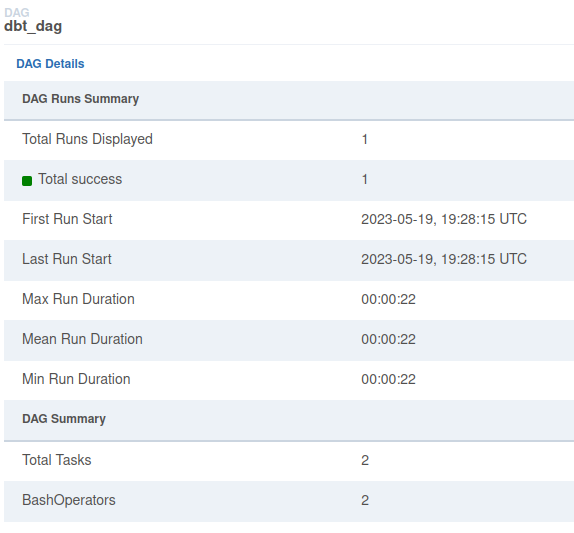
So as we can see, the start was almost instant. The total elapsed time is 56 seconds.
Dagster
Shortly about the tool:
Initial release date to public June 12th, 2018
v1.0 August 5th, 2022
Elementl is a company that provides SaaS tool for Dagster
In all the clouds, you should compose it on your own and manage yourself; no option to have a kind of vanilla adoption of it there.
Adoption:
Slack: 6.2k members
Github Stars: 7.3k
Downloads PyPi: 526k/month
No Docker pulls statistics since Dockerfiles you’re creating is based on Python images.
Architecture

Technically if you look closely enough, it’s quite similar to what Airflow has. Have a Web Server, have a Daemon that behaves like Scheduler and then Executors. The only thing is that you can easily mount multiple repositories and make them available through gRPC; this, you define in the workspace.yaml file.

So, you can plug and play multiple repos, allowing your teams to work independently.
Now about the terminology, what’s new here (at least name-wise):
Asset - Same as a Dataset in airflow in a way, though the whole flow for the so-called asset should be defined in the method you’re putting a decorator upon.
Op - short for operation, technically it’s the same as a task in airflow
Resource - an analogy for airflow connections.
Job - equivalent to a dag in Airflow.
User interface

UI is clean and straightforward, with jobs on the left; some asset group section, too - looks like a bit advanced feature, most likely because I’m not quite sure how to use it.
Let’s check the job section (fast-forwarding a couple of more clicks):
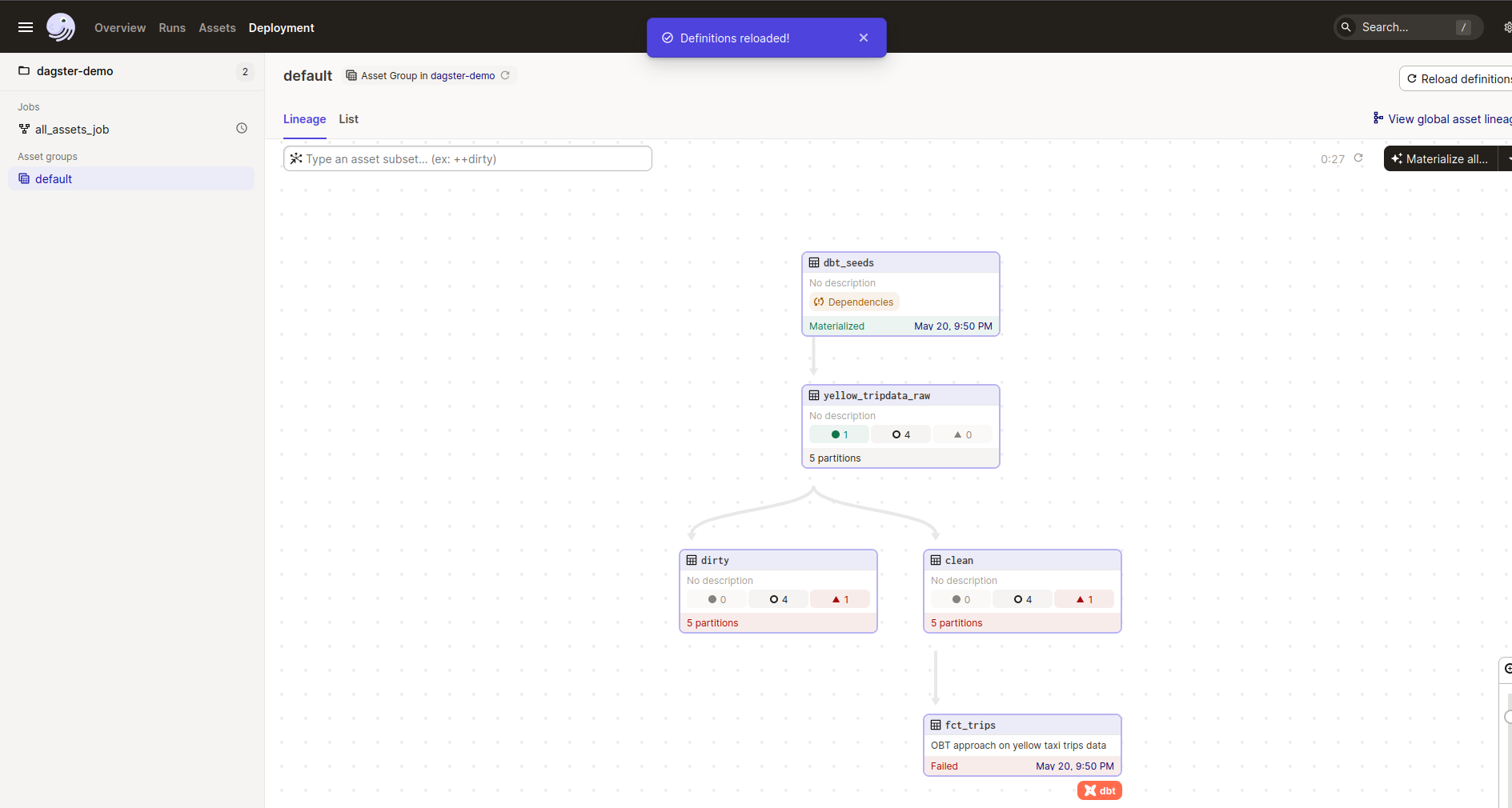
Now the exciting thing is that I spent quite a while creating an assets folder properly instead of loading one file with everything inside and at least tried to create some structure for this blog post. This gave more a bit more understanding of how it works, but still, I feel pretty unsure if it is good practice to do what I’ve done, but at least now I can work in a similar way I’m used to doing with airflow - mount assets in Docker-compose and make refresh smoother.
Another note is that here dependencies are a bit off. dbt seeds are running before raw extract. Here it’s done to mimic one dbt seed run before fct_trips runs. At the end of my Development Experience, I will add more with each tool, so bear with me.
Dagster Code
Directory structure:

Extract:

Transform (without the helper function (though it looks a bit lazy to me, could have removed recurring information or maybe moved to commons, but it is what it is):

And dbt part:

All of them were defined in different files; so much flexibility! Especially since I don’t have to worry about creating dbt models and dealing with dependencies since Dagster does it for you!
Now about the speed (I guess I messed something up while doing the presentation since numbers are quite different):

We can see that in between tasks, we have ~10s gaps; I assume it’s the time for a new process to spin up. I am also interested to see if it takes that much on production systems. So the same job took 1min 38s.
Bonus
After some runs, the “Overview” tab looks a bit better, and more information is there!

Mage
Some dates:
Company was established on December 1st 2020
First public release June 9th 2022
It’s not entirely clear on licensing, so some interesting things might be later when comparing Dagster and Airflow, both under Apache 2.0.
Architecture
I couldn’t find an image of it, so I'm jumping to the assumption that it’s most likely similar to Airflow and Dagster.
Metadata DB
Web Server + Scheduler (in their docker-compose, seems to be coupled and named as “Server”)
Executors
User Interface
I will cover some terminology here since it looks like a better fit.
Code is split into different so-called “Blocks”, and they can be various types:

and you can choose from pre-created ones if they fit your needs.

Ok, getting back to the UI itself:

Dark theme out of the box, FTW!
The whole development experience seems to be aimed at being moved from IDE to their provided Web UI, and the pipeline process reminds me a lot of jupyter notebooks.
Bonus: dependencies can be adjusted with drag and drop from the UI.
Mage Code
Extraction:

Cleansing, at least I couldn’t find how to re-use one method in a couple of places, but this seems like just me not knowing the tool properly.

dbt part is the same as in Airflow, with separate blocks, with manually typing things and seeds run as bash command:
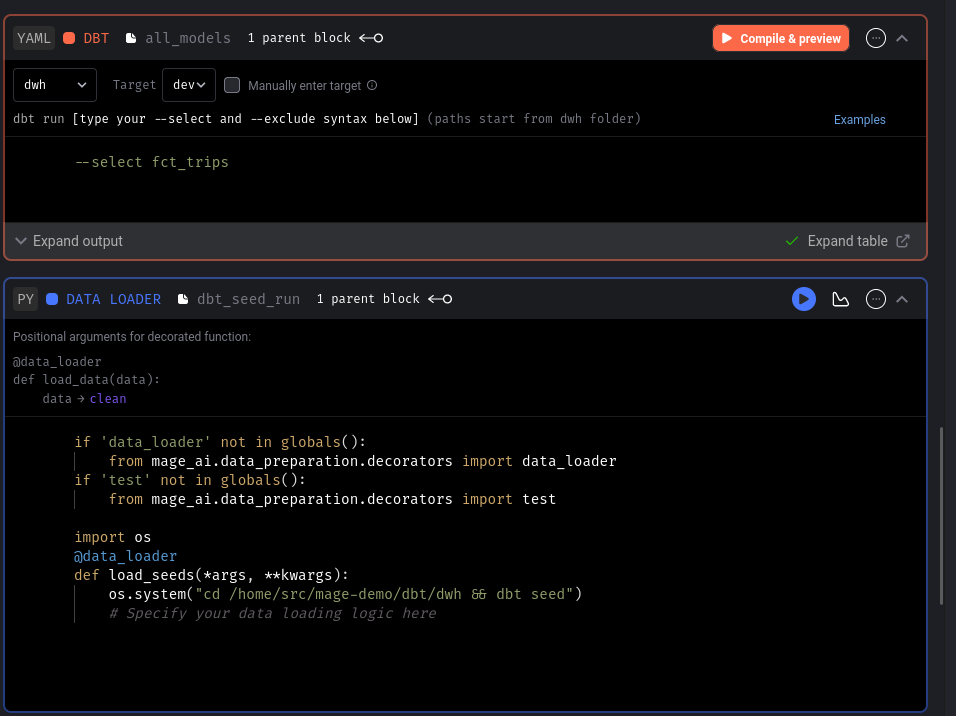
All in all, it looks like this

Runtime wise less than a minute. So the faster of them all is because that webserver and backend are on the same machine, so no serialization/deserialization causes speedier execution.
Thoughts on contenders
Dagster:
Pros:
Perfect for dbt usage. All is done Out of the box.
It can be quickly adopted in decentralized teams with multiple repositories but still executed in the same Dagster Environment
Lineage out of the box
If you’re coming from Airflow easy to adopt and use
Prepared scripts/helpers to move from Airflow
Feels a bit cleaner and lightweight
Cons:
Harder to get a grasp of the infrastructure side for the dev environment (interesting to see production-grade deployments)
It seems Slower than Airflow and Mage because of starting up, might be some internal things I’m missing
ChatGPT and Copilot don’t help much; the new architecture is fresh, so for now little use for these helpers
Community is Still relatively small compared to Airflow
For me, what matters most is developer experience. I liked that dbt things are done out of the box, but I’m not sure how to plug more things as dependencies that are not sourced inside dbt project. Backfilling can quickly be done from the UI, while, i.e. in Airflow, it’s more like clearing the tasks in UI or using API, but what if I want an easier way?

A lot of flexibility to backfill; that’s harder in Airflow.
Jobs can be turned off in code only, so at least you’re version control safe from accidental turn-ons or turn-offs.
Mage
Pros:
Dependencies creation drag and drop
Notebooks approach (personally for me, I'm not too fond of it, but I see why others would like it)
Dark theme
Quick support
Has streaming pipelines (Kafka only, so most likely using Kafka library for Python)
Cons:
Dependencies creation drag and drop - was a bit tricky; in some situations, it wasn’t working as I expected, I had to edit using the parental dependencies section.
It stopped working a couple of times, but I got fast support from the CEO and CTO in Slack. Though in some situations was strange that it worked and then it stopped (might be M1 related)
Web IDE - more distractions compared to fully zoning out in my VSCode.
A lot of YAMLs, hard to navigate.
dbt has to be in a specific place, same for profiles.yml file. Very little to no customization
Tiny community (but founders are making themselves visible, pairing with data influencers and meetups, which might grow at some point)
These are not the best impressions I had, and most likely, I won’t be the target audience for the tool since I hate the notebooks approach (sorry, Databricks), plus hiccups along the way with the tool itself.
But as always, let’s see where the tool will be in a more extended period; I might change my opinion.
I have some doubts about coupling the web server with the scheduler on scalability, but maybe that was the intention for speed and smaller workloads.
Summary
Both contender tools have their good sides and place in the different sides of the data community. In my eyes, Airflow will reign supreme over them (at least for 2-3 years) because of this massive advantage they have created by the community and companies/people using it, also with powerful templating capabilities. Yes, I’m turning more into a YAML engineer, but it’s more efficient. However, it might be wrong with Dagster’s pre-made migration scripts.
I was a bit worried that nothing significant is being released there to address, i.e. Dagsters dbt parsing, Datasets, had doubts if Airflow can run continuously, etc. But I see the cosmos library (pushed by Astronomer), Datasets are there, there is a continuous schedule, and even solving hung tasks that were bothering me is resolved.
So at least for an upcoming couple of years, it still is here, worst case, same as Hadoop or maybe like COBOL, where you have people running it until the end of time.
So for now, what I think would make Airflow still king is to take the best out of the competitors and apply it, not to lose people there:
Easy backfill in UI for all related Datasets (might be coming, but Datasets feature is not that old)
Configuring outlets, but we don’t use inlets (would leverage complete lineage)
Maybe at least do a mock UI where we could more easily define dependencies (but not sure about this, since i.e. I’m usually dealing with a lot of templated frameworks, so my work is way faster and easier, so just have to be right in the development phase)
The code can be found in my Github Repo:
https://github.com/uncledata/airflow_dagster_mage