
Oh, my dbt (data build tool)
My experience and a couple of notes of using this superb tool for a month

Introduction
All my life, I was working with data. Somehow it sounds dramatic when I put it like that. Basically, I've done some analysis and basic work with SQL as a Business analyst, but nothing where I’d need templating. So-called BI career I started in 2013. Being a consultant and working mostly with MSSQL on multiple similar projects, it would have been a blessing to have something like dbt (or at least to know about Jinja at that time…); let’s write it off as a lack of experience.
Funny that I tried dbt only now. If I’m honest with you — I’ve been using it for ~month, so keep in mind that I’m not a pro, just spreading the knowledge and sharing what I’ve found. You can find many other medium articles on some specifics or go straight to the source of dbt.
Prerequisites
First of all, for this to work, you’d need Docker. If you’re not familiar with docker, I will promote my older blog post I wrote some time ago about it. When working in docker-created environments, I prefer to use VSCode with its dev container option, where it basically creates an isolated environment with all my configs, mounts, etc. If you make any changes to the existing docker image, you can choose the option rebuild image, and it will compose it and open it for you with all changes. Super handy if you’re developing things so that you can skip manually doing docker-compose.
In my docker image, I’ve created a specific docker-compose file with two components — simple postgres:13-alpine and python 3.8. Choosing python 3.8.11 over 3.9 — had some issues trying to install dbt because of compatibility issues. I’m also using the mount option in my docker-compose file to pass the proper profiles.yml file for this specific project.
Postgres Dockerfile:
FROM postgres:13-alpine
ENV POSTGRES_PASSWORD=nopswd
ENV POSTGRES_DB db
COPY init.sql /docker-entrypoint-initdb.d/In the init.sql file, I just created a database named db.
Python Dockerfile:
FROM python:3.8
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txtNothing fancy in requirements, just the dbt library.
If you have already a production environment with dbt and you’re setting up a local one — always use the same dbt version as you have in production. Had trouble on dbt run, but my colleagues didn’t. Root cause — everyone was using 0.19.0, and I installed the latest at that time 0.19.2 and some compatibility issues occurred for dbt deps we had in the packages.yml file.
Docker-compose, as I mentioned, has some more things, but nothing fancy:
You might be wondering why I’m opening the 8001 port — it’s needed for some dbt feature you’ll see later on.
Getting started with dbt
Ok, what is this dbt, you might be wondering. Basically, it’s an amazing tool to ease your transformation part in your ELT flow give you data lineage, documentation, and full control on data refreshes if some underlying data changes in one of the models somewhere in the middle. I really don’t want (and usually don’t like) to go to product details since I’m a more technical person, not a product one.
Ok, so there are a couple of important files in dbt.
profiles.yml — file where you set up all connections and how you’re going to use them
dbt-project.yml — specific configuration for specific dbt project you have this file in.
Let’s go over the profiles.yml file:
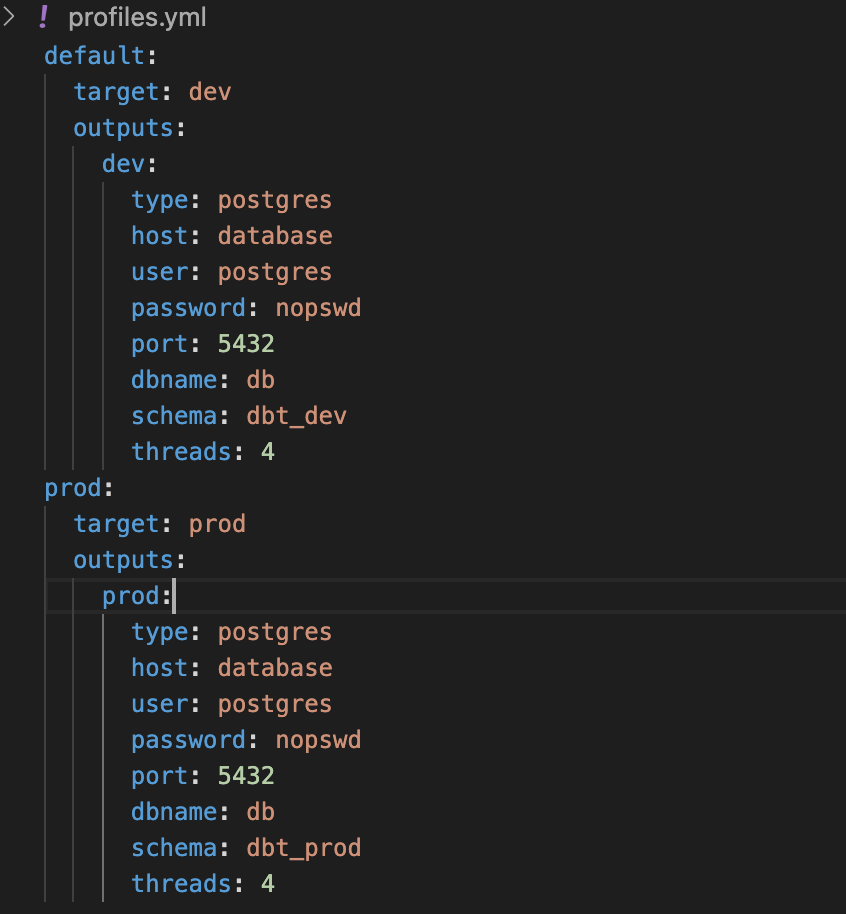
We have to have a default profile; this will be where everything is run if nothing else is specified. Different profiles will allow you to easily test pipelines on different environments (i.e., test and prod):
# Running on default:
dbt run# Running on prod:
dbt run --profile prod# Running on default with specified profile:
dbt run --profile defaultAfter playing around in VSCode opening my folder in the development container, it’s interesting to see if all works as intended.
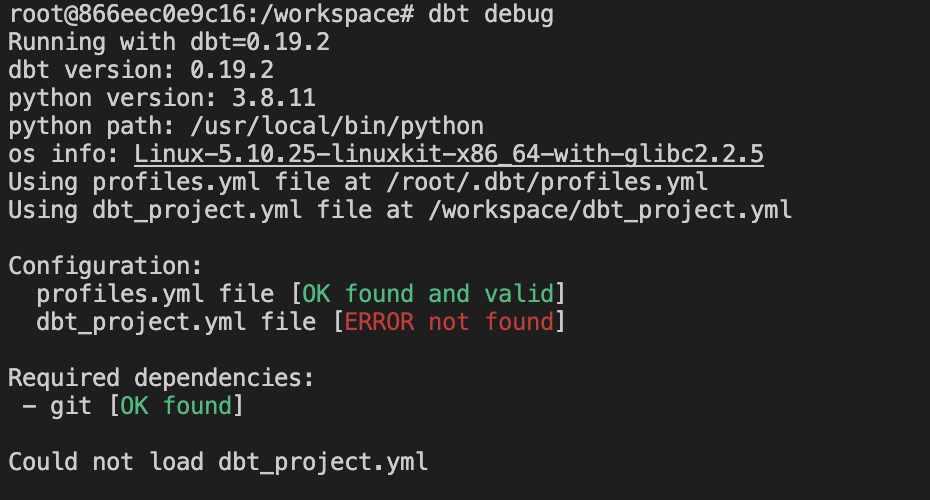
As you see, we have one error on dbt_project.yml. Let’s fix it.
For simplicity and keeping the original dbt structure, we can initialize it. To do this, let’s run this command:
dbt init MY_DBT_PROJECT_NAMENow we can see what’s the structure dbt expects us and how it works with:

Let’s check if everything else is working from this folder and properly created profiles.yml

Great success! Our environment is fully functional and ready for us to check all things out.
Let’s try dbt run on the default profile:

We see that we have two models (which correspond to two files named my_first_dbt_model.sql and my_second_dbt_model.sql), but what are these tests? Where do they come from? Let’s dig deeper into the model's folder.
We can see we have schema.yml file with contents

We can see that we have two columns described plus tests — a column has to be unique and not null.
I found that my colleagues are creating a yml file per each model. In my opinion, this is a better option:
visually looks more clear
no merge conflicts because, most likely, there will be one developer per one model!
If we’d look at the queries their straightforward. Creates a table with 1 and null, creates a view out of the first table where id = 1. But wait — our tests didn’t say that we failed. We have a null value! That’s because it doesn’t have any data to test upon. So after we run our model, we need to test it.
To run tests:
dbt test --model exampleOutput in the console will look like this:
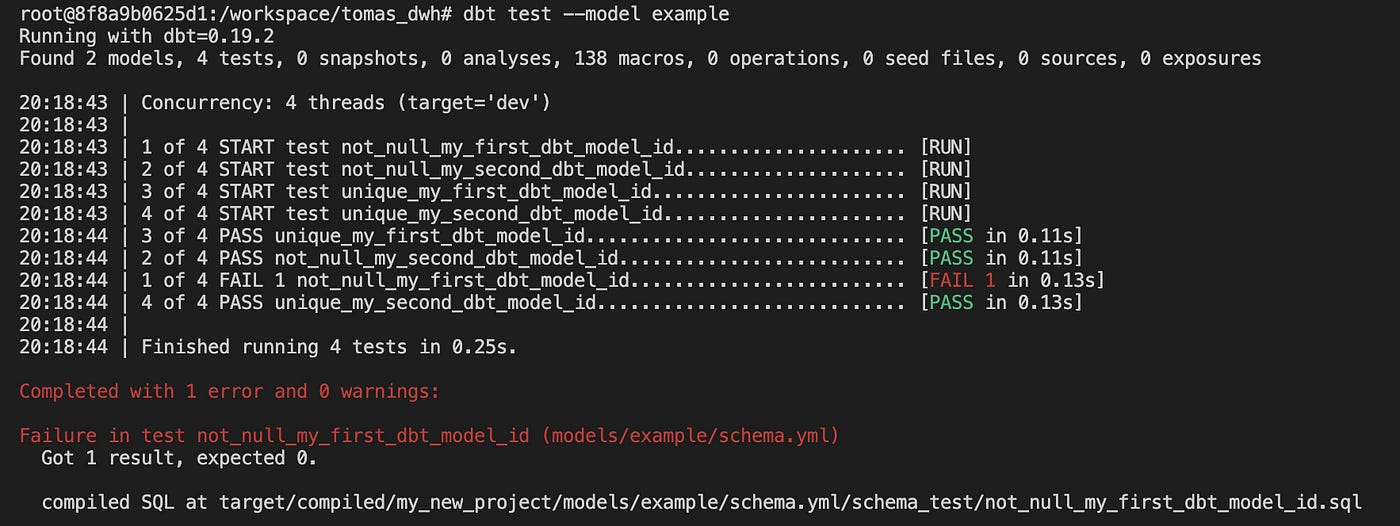
Clearly, we can see that there are some issues on our end and, we need to fix them.
The fix is easy. Let’s switch from null to some number and test again. We'd still see the same state if we’d run directly “dbt test” after the fix. We didn’t run the model, so underlying data didn’t change. We need to run and test it.
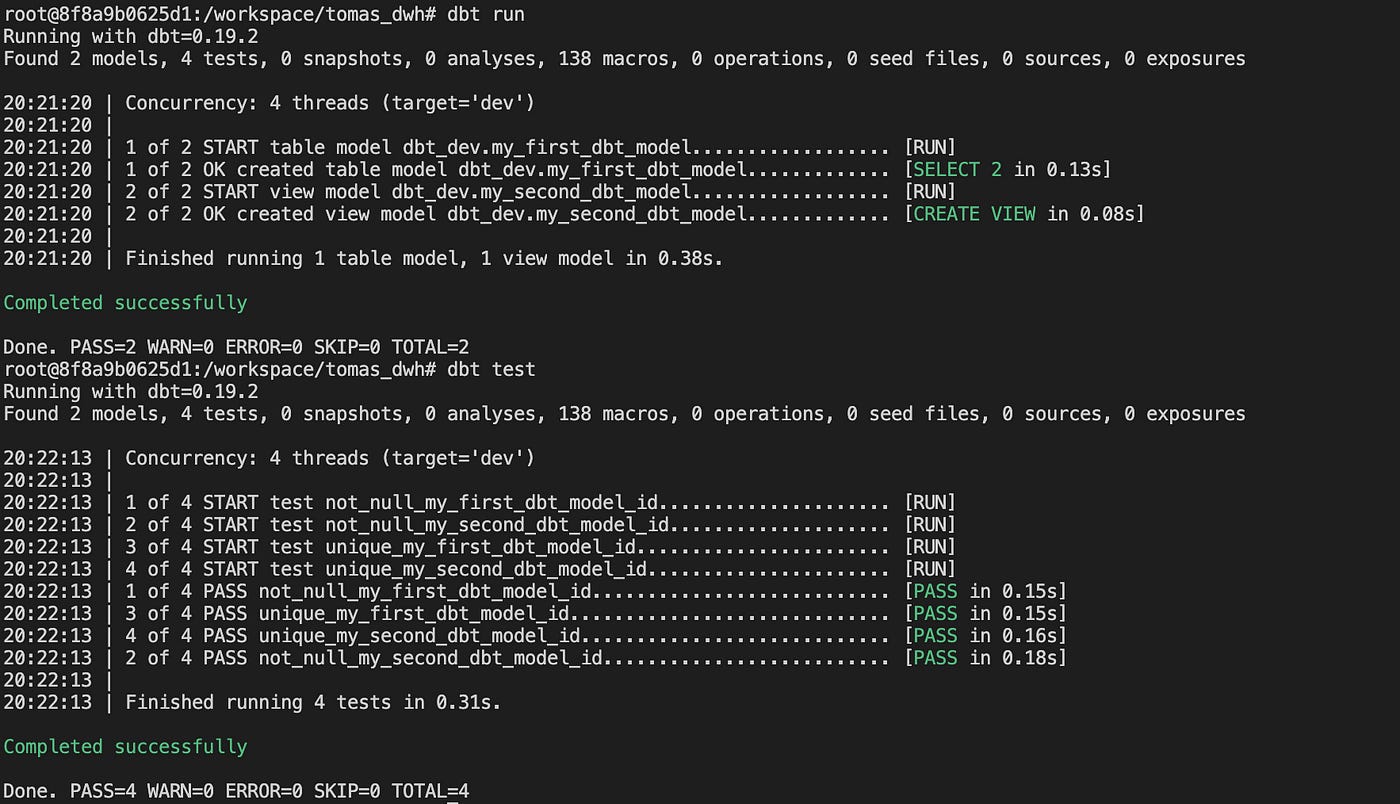
Hooray, we just fixed and ran our models successfully!
If we’d run dbt run on both dev/default and prod, we’d see in DB all of this
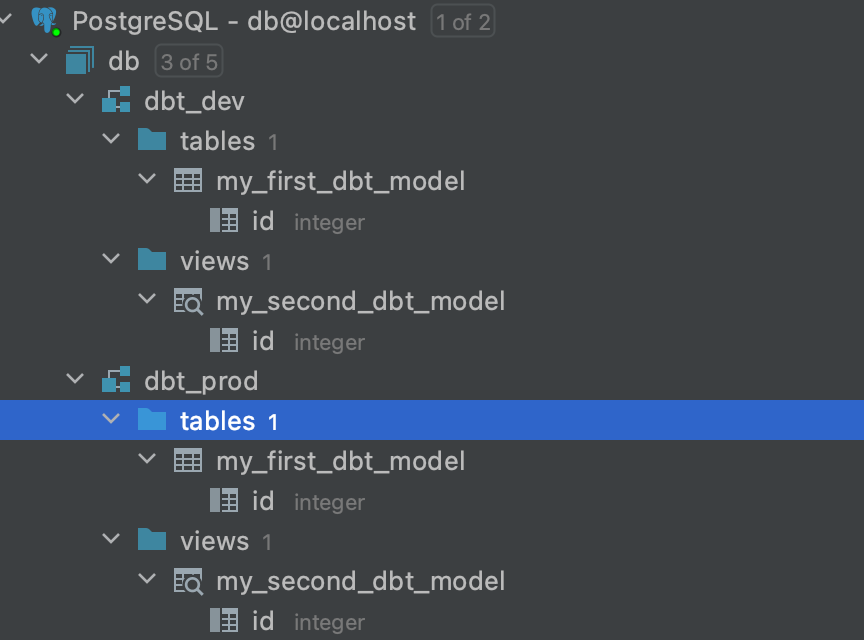
dbt specifics
Target folder
After our dbt run, we had this folder created. Its contents:

For me, the interesting files are in the compiled/run directory. If we go down the rabbit hole, we can find our SQL queries parsed.
We also could compile our files by executing:
dbt compileRun would create or update files in compiled and run folders. You’ll have tests SQL compiled as well, so you can understand what was being run in your specified tests.
Logs
If any issues occur and it’s not quite clear what it is - check logs/dbt.log. i.e., At work, I got “Database Error: permission denied for database X.” I have no clue what permissions I was lacking. I got a link to debugging page of dbt, and my colleague said to check the logs. From there, I found what permissions I was missing.

Incremental model
Let’s imagine we have a situation where our data residing in DB is big, and we want to add incremental load. Generically we’d do one script if a table exists — create it from scratch, else — insert and (or) update it. So basically, we have repetitive parts of code, and we have to maintain it in two places. It doesn’t comply with DRY (Don’t Repeat Yourself). Luckily dbt has an amazing feature like an incremental load. For this, we’re going to create an additional source table using Mockaroo. I’ve executed 01_mock_users_data.sql on my local Postgres database. I also made a small change and converted the created_at column to be a timestamp column instead of a date.
Created a simple model to use is_incremental macro:
If we’d run it now and check target/run:
create table "db"."dbt_dev"."mock_users"
as (
select * from "db"."operational_db"."mock_users_data"
);Let’s run 02_more_mock_users_data.sql and do dbt run again. In target/run, we can see different outputs!
select * from "db"."operational_db"."mock_users_data"
-- this filter will only be applied on an incremental run
where created_at >= (select max(created_at) from "db"."dbt_dev"."mock_users")Though nuance here that it will run exactly by filters you specified. The first run will be for ALL history; the next run will be for only new rows. The initial query might not even finish or encounter some other issues along the way (timeout, some hard limits on query run time, etc.). So you could go around and create an upper bound filter where you’d take only a couple of days/weeks/month and easily refresh it like this in several batches. Though it’s tedious, and you’d have to run it manually to catch it up.
Macros + insert_by_period
Disclaimer: insert_by_period works with Redshift only, dbt-vault created vault_insert_by_period works on Snowflake. So basically, I’m just explaining my journey what I tried and checked along the way.
I mentioned in incremental load “Macros,” you might wonder what it is? It’s some custom code, which is executed to add some missing functionality or more complex logic. I.e., mentioned before a tedious incremental load. In our case is a simple conditional insert that would load our initial data in multiple batches. You can check it out in the original discussion about this macro here. All in all, it’s bundled in the dbt-utils package. We can import by specifying it in the packages.yml file. Version 0.7.0 wasn’t compatible with my dbt version of 0.19.2 (asked for 0.20, which is only a release candidate at the moment this blog post was being written), so I used 0.6.4.

and we can install dependencies with
dbt depsIf we’d follow all the information for the version for our Postgres use case, it won’t work, since as it’s written in the comments - it’s suited for redshift only! After this, I went into the rabbit hole, checking dbt-vault, making some adjustments, and creating my own macro using comments in GitHub. But I guess I’m too new to macros, an advanced topic, and I couldn’t make it work. I will have to dig deep on this later.
Snapshot model
The name of it doesn’t really explain what it does. At least to me, a snapshot means the current state of the data. Though in the dbt case, if we create a snapshot model (they suggest putting it in the “snapshots” folder), we will have SCD type 2 (by the way, I wrote an article on SCD2 on spark some time ago, which covers what’s an SCD).
So let’s use the same mocked users data for this example. Let’s add the updated_at column and make it match to created_at column (03_update_at.sql). Let’s follow the basic example from dbt docs and run dbt snapshot. We can see how the snapshot looks like (only interested in newly added columns):

We can see that we have dbt_scd_id and dbt_valid_from and dbt_valid_to, corresponding to the changes. Let’s execute 04_change_some_names.sql and run dbt snapshot.

Ok, so basically, we just set up what’s unique, and dbt took care of the rest. Now that would have been handy many times for me. Looking in the target/run/snapshots folder, we can see our snapshot code was generated for us too!

So basically, we can see that it created a temporary table and then made all comparisons for us!
Generate docs
Data lineage and documentation. If you specified all relevant metadata in your yml files and used references to models and sources, you can generate documentation!
dbt docs generateThis method will generate a catalog.json file in your target directory. To check how it looks on the web:
dbt docs serve --port 8001 // or any other port you prefer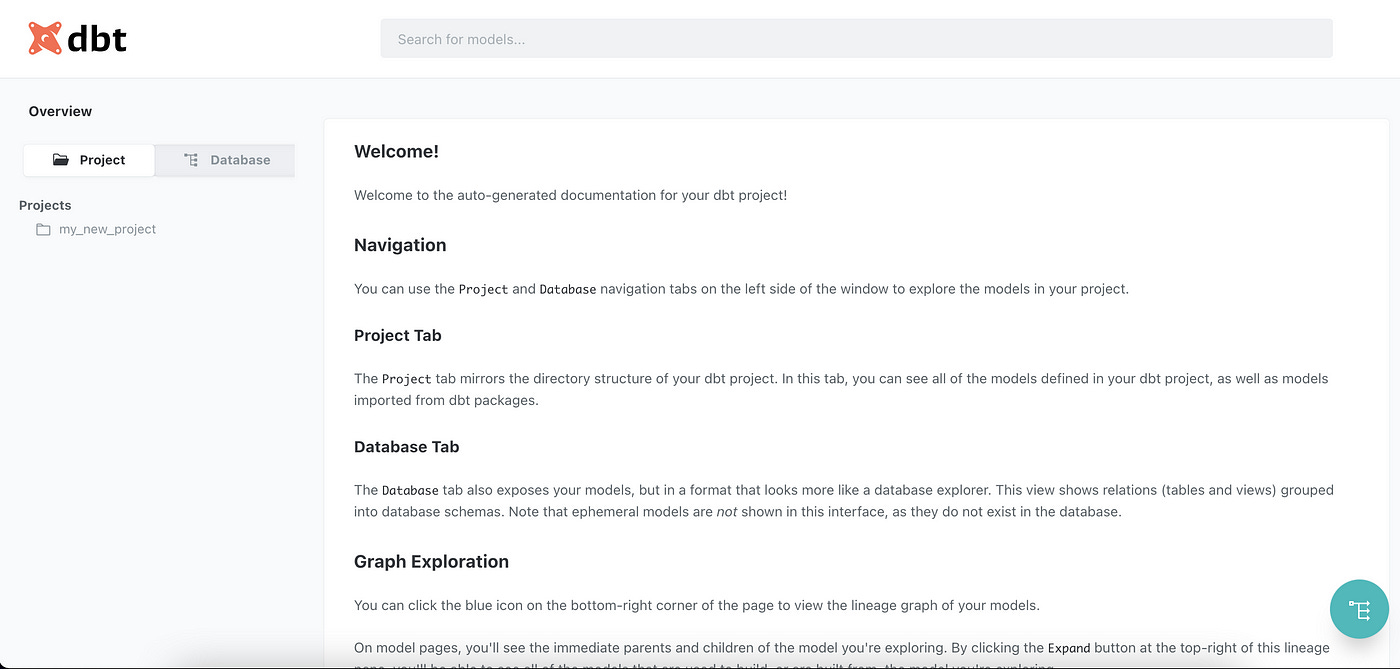
If we’d click on the greenish icon bottom right, we’d see lineage!

Keep in mind that here I show basics. Tons of things are on the official dbt page (dbt-docs page)!
Summary
So we covered most of the basic things (I found out an area of interest -> macros). Strongly suggest to anyone who’s working with the ELT approach to try out dbt. This will allow you to leverage it fully: full refreshes, downstream re-runs, documentation, and data lineage.
You can find my code in my GitHub repo.