
PySpark: Avoiding Explode method.


In this post, I’ll share my experience with Spark function explode and one case where I’m happy that I avoided using it and created a faster approach to a particular use case.
Disclaimer: I’m not saying that there is always a way out of using explode and expanding data set size in memory. But I have a feeling, that it’s like 99% of use cases can be figured out and done properly without the explode method (I know, I know… going with gut feeling is not that professional, but I haven’t encountered one case yet, where I would not think of an alternative to explode).
So what is this spark function Explode:

Basically we create multiple rows of almost identical information, but one column has values split per row.
Mostly if you’re working with structured data you probably won’t think of using this method. But some time ago I was doing some processing on NoSQL type documents. My issue was to extract particular IDs from a double nested document (i.e. one column was a separate array of JSON with nested information inside in similar matter…). For this not to become a rant how I hate dealing with these kinds of structures I’ll just move along and get to the point of my task.
Basically I needed to filter the first array on a particular column and do additional filtering on the underlying JSON there… Haven’t worked with such nested structure I thought — it’s JSON, I’ll just simply call it… and then it hit me, I have no clue which array member will have this information for me to call it. Googled a bit and saw explode. The performance was poor (the dataset was huge) and I had to fine-tune it. The next part will be exactly what I did and how got rid of explode method.
Let’s do a hypothetical example. For this, I’ve created a mock JSON file using this link. The structure defined by me (very simplified variation of my task for the even simpler task. BTW: id field as a unique identifier):
And let’s simplify the task itself. Read JSON, get ID’s who have particular creator Dotson Harvey and put it as a parquet file.
Disclaimer: Better safe than sorry — All data here was mocked using the link I’ve provided above. All resemblance or matches for real existing people are purely coincidental.
So I’ve created these two methods which do this:
Note that I am specifying the schema of a file, so spark wouldn’t read the file to infer the schema.
Note 2: Apparently I didn’t think this through and did it without distinct() and my Dotson Harvey could be several times in the application array and it made some IDs appear several times…
The average execution time for this took around 1.6s (mock JSON is not that big). Execution plan:

So since my task is just to get id’s with at least one app of Dotson Harvey — I thought maybe I can use regexp_extract() to see if it returns a match. But I need to specify a different schema when reading the JSON initially.
Since I’ll get the first match on a string I won’t have duplicates. And the execution plan for it:
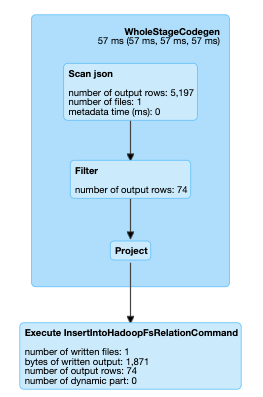
So we just cut a bunch of additional stages here. The average run time was 0.22 s. It’s around 8x faster.
For those who are skimming through this post a short summary: Explode is an expensive operation, mostly you can think of some more performance-oriented solution (might not be that easy to do, but will definitely run faster) instead of this standard spark method.