
Write-Audit-Publish Pattern in Modern Data Pipelines
Post is going to be a written expression of a talk I gave at PyCon Lithuania 2024


Introduction
Why am I talking about the Write-Audit-Publish pattern? I’ve chosen it because I see it becoming popular in a few years. However, when I gave my talk, I thought only 5-6 people knew about this pattern. But before diving into this, I want to explain where I saw and used it.
You can also imagine me a bit like

Since the tech I used is quite old and some people don’t know the pains I had to go through 😅
When I was doing BI back in ~2013, we heavily used SQL Server (SQL Server as DB, SSAS as OLAP DB, and SSRS for reporting). At least in Lithuania, this tech was very popular. I had quite a good experience with it, which gave me a good foundation for my current knowledge.
Regarding the pipelines and flows, all tables had proper Primary and foreign keys set, and we had constraints that would fail the pipeline if they were violated. I was 100% sure that no 💩 data would fall through anywhere. It was because you would first have to load Dimensions (Primary keys) and only then fact tables or other ones with defined Foreign key constraints. This kind of approach is what ETL was meant for:

The interesting thing is that around that time, we started the rise of Hadoop and Big data, and this hype came to Lithuania around 2016-2017 (maybe I’m wrong, but I remember this thing happening at least in my social bubble). With all the big data hype, people started to see that ETL is slower for big data flows (even now, joins are an expensive operation with all the advancements in technology and frameworks), and we started to see the rise of ELT.
Back to basics
I mentioned PK and FK and check constraints before, but let’s cover those in just a bit more detail.
Entity integrity - Primary key, Unique, Not Null, etc.
Domain Integrity - Check and Default constraints
Referential integrity - Foreign key
User-defined Integrity - Indexes, Stored Procedures, triggers
You can already see that all these checks are important now but in a slightly different context. I.e. dbt popularised data tests that you can run on your refreshed data asset; you can easily add all these integrity checks. If you’re using the dbt-expectations package, you have a pretty big coverage of your data quality.
So why has data quality started to be important?
When COVID started, companies realized they had tons of irrelevant data or their quality levels were 💩. Fast-forward to now, where quality is even more important, just because of LLMs and Generative AI. You can see that the market for data quality-related tooling is also quite big.
.

Apart from GenAI and LLMs, people making decisions must trust your data. If they don’t, they will return to gut-based feelings instead of allowing their gut-based feelings to be influenced by data.

As you can see from the State of Analytics engineering report, very little will be reduced, some will be maintained, and some will even increase investment. Data is new gold, but it’s useless for end users if it's not refined.
Data Pipelines Currently
Image in a better resolution from video:
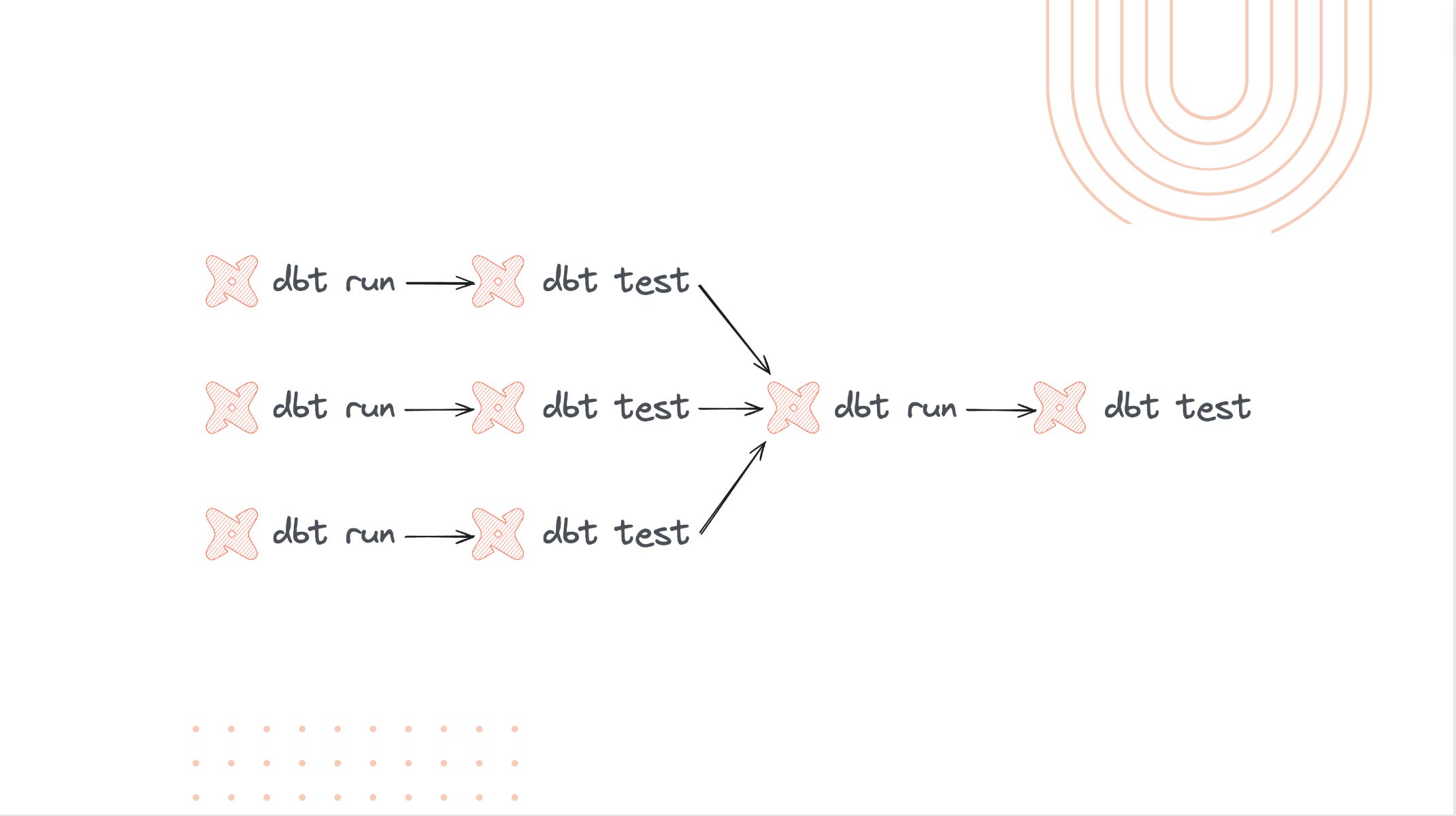
The problem arises when the data team size grows, and you want more speed and have fewer hard dependencies between different areas. This leads to the separation of your flows into different DAGs that might lead to crappy data leaking through cracks where some dependencies are set incorrectly and potentially can lead to poor decisions being made and, later on, losing trust in data.
What’s Write-Audit-Publish?
It’s this in a nutshell.

You run your pipeline somewhere else (different schema, maybe in memory, etc.), run validation and only if all passes you push it down to production.
You can also read a lot about in this blog post
Potential solutions
DIY with Dataframes
In my presentation, I used the example from that blog post. Clean and filter the data frame; if the row count is decent (or at least not 0), write it to storage to raise an error. If something fails, you must run all your flows repeatedly for debugging.
Another option is to store results in an intermediate place and then run data quality. If all succeeds - move to production. Data is materialized a couple of times, and it takes more computing than needed, but you have a place where you can investigate what is wrong and make adjustments if needed.
However, this whole thing requires quite a lot of engineering effort.
Snowflake Zero-Copy Clone
When working in one of my previous companies, I saw a neat approach in doing WAP, with just a bit of overhead.

All your dbt assets consist of these steps. If tests pass, data is only moved (only references are copied) to the user-facing database. We had a similar but modified approach, where we didn’t want to show any data if we had issues. We ran all flows, and only when all tests passed, we zero-copy cloned the database for our stakeholders to see.
Apache Iceberg: Branches
So, around a year ago, they released this feature. What it actually does is bring Git-like functionality to your data.

You have to do a couple of things:
Enable WAP for a table
Checkout a branch
Go crazy on your data
Fast forward the branch to the main branch
The code looks like this (very, very simplified version):

If you like, you can make wrappers that would create your branches with relevant names in each of your flows, and then you can have it automagically, as I like to say.
Notable mention
There is LakeFS by Treeverse (they also did a presentation on data version control during PyCon Lithuania a bit after my talk, so this is a tiny addition). They give you this functionality with a friendly GUI and all history in a pretty way.
However, it doesn’t make sense for you to move to Apache Iceberg if you already use it.
Million dollar question
So, to WAP or not to WAP? It's a fun thing, like always in data - it depends.
Benefits if you’re WAP’ing (I’m explicitly aiming here at the use of the Apache Iceberg Branches feature!): you can use whatever tooling you want, a complete state is available for human intervention is needed and you can also push multiple tables to be attached to a specific branch so that you can treat them as a single transaction (throwback to the good ol’ RDMS days for me).
If you’re not using Iceberg, then it might be a bit more complicated for you to have this neat OOB experience. The biggest downside is that people in the industry have very little knowledge. This is because many people in data joined in the last 3-4 years and haven't gone through the RDBMS DWH flow; they went through the cloud-native approach with so many different technologies available at arms reach.
If you like, you can check out my slides used for this presentation here.