
Is it the end for Apache Airflow vol. 2
Trying Prefect and Kestra with same use case to see how it compares to the other orchestrators.

The post is too long to fit into an email, so check it out at my substack page for a full read.
This is the continuation of my previous post/talk I did. In case you want to read it, you can find it here:
Is it the end for Apache Airflow?

This is the extended version (though without some of the jokes I made on stage, but with some new ones!) of my presentation with more details, some dives into the code and my struggles that weren’t mentioned in the talk I gave at PyCon LT 2023. Since it’s a long post, it won’t fit into an email, so if you’re interested in what I have to say - open on su…
In this post, I’ll run similar (or as close as I can get to the ones I ran in originally) with Prefect and Kestra.
Note: I’ve switched to Macbook Air 15" with an M2 chip, so runtimes will differ because of the newer chip. I will NOT run Dagster, Mage and Airflow again. Just will reflect in a similar matter and compare to what has stood out to me.
Previously on “Is it the end for Apache Airflow.”
The challenge

The simple schema looks like the one shown above. The orchestrators’ job is to do it all. The dataset available via HTTP request was the one and only Yellow Taxi data.
The fun thing is that now I’m losing the homework assignment that I send to candidates when hiring Data/Analytics Engineers, and this solution I’m providing is a fair enough solution for them to pass the Junior-Mid role bar (of course, more things are always better).
DWH, in this scenario, should look something like this:
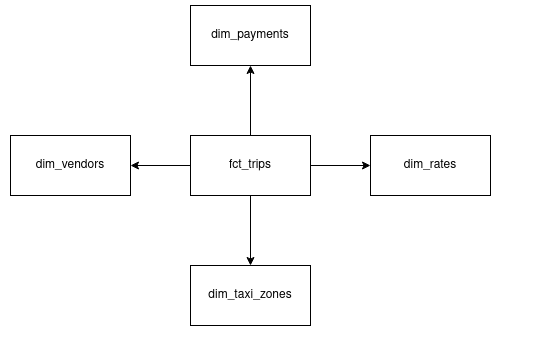
Prefect
Some dates:
First 0.3.0 release Aug 20, 2018
v1.0 on Feb 24, 2022
v2.0 on Aug 1, 2022
As you can see, between v1 and v2 was around six months, so quite a lot was done to release a new version.
Prefect is a company that also provides a SaaS-based solution.
Looking at the community:
Slack: 25k members
Github Stars: 12.3k
Downloads PyPi: 670k/month
As you can see, it has more similar adoption to Airflow compared to Dagster and Mage. It looks like we’re off to a good start.
Architecture
Since it’s already on v2.0, I will look at its architecture.
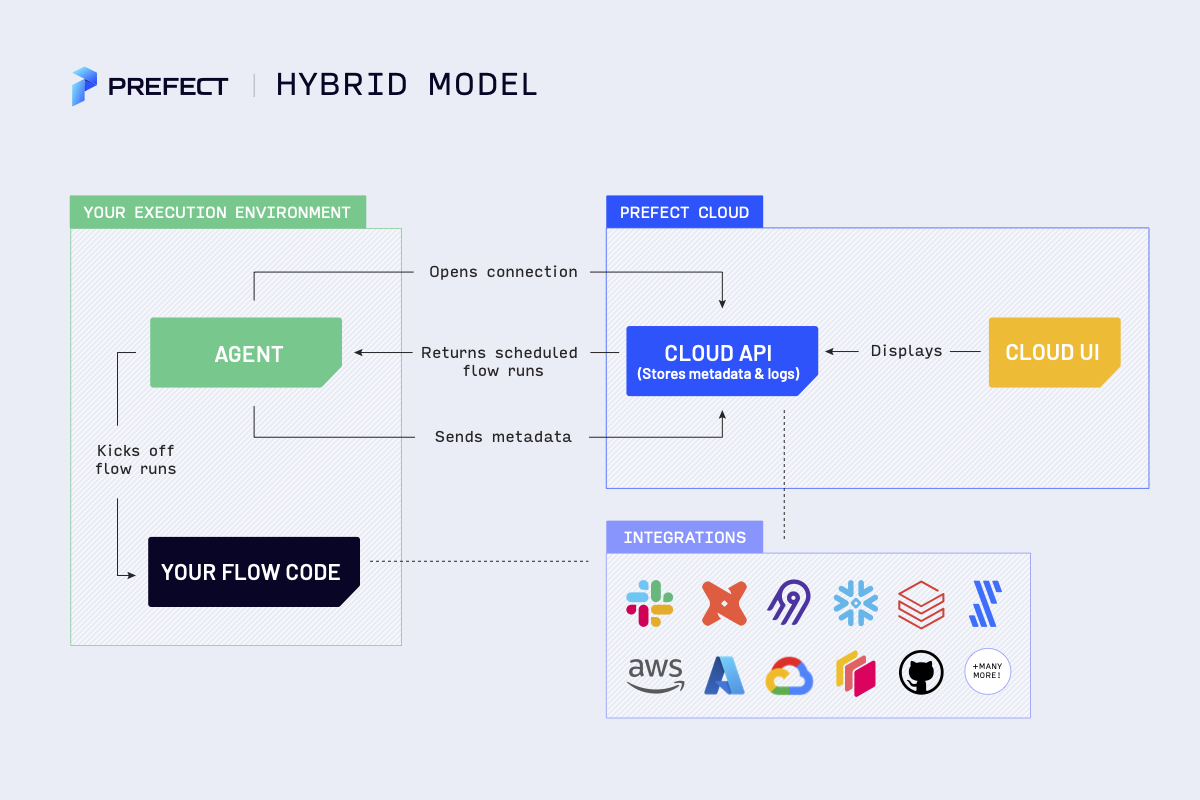
The only note is that for the OSS approach, we have a Server instead of Prefect Cloud that covers the API and UI part.
About the terminology, same thing, but different names as usual.
Flow is a DAG in airflow — a collection of tasks to be executed.
FlowRun -> Dagrun, etc.
We also have a new deployment, combining a schedule, environment and what will be executed.
User interface

All looks quite straightforward! Note: Blocks are actually how you define connection objects like in Airflow.

It’s a bonus for me that I don’t have to think about how to pass env variables to the system or create new ones on the fly from the UI.
Code
With minimal changes to Dagster code, I could get it up and running with Python executor:
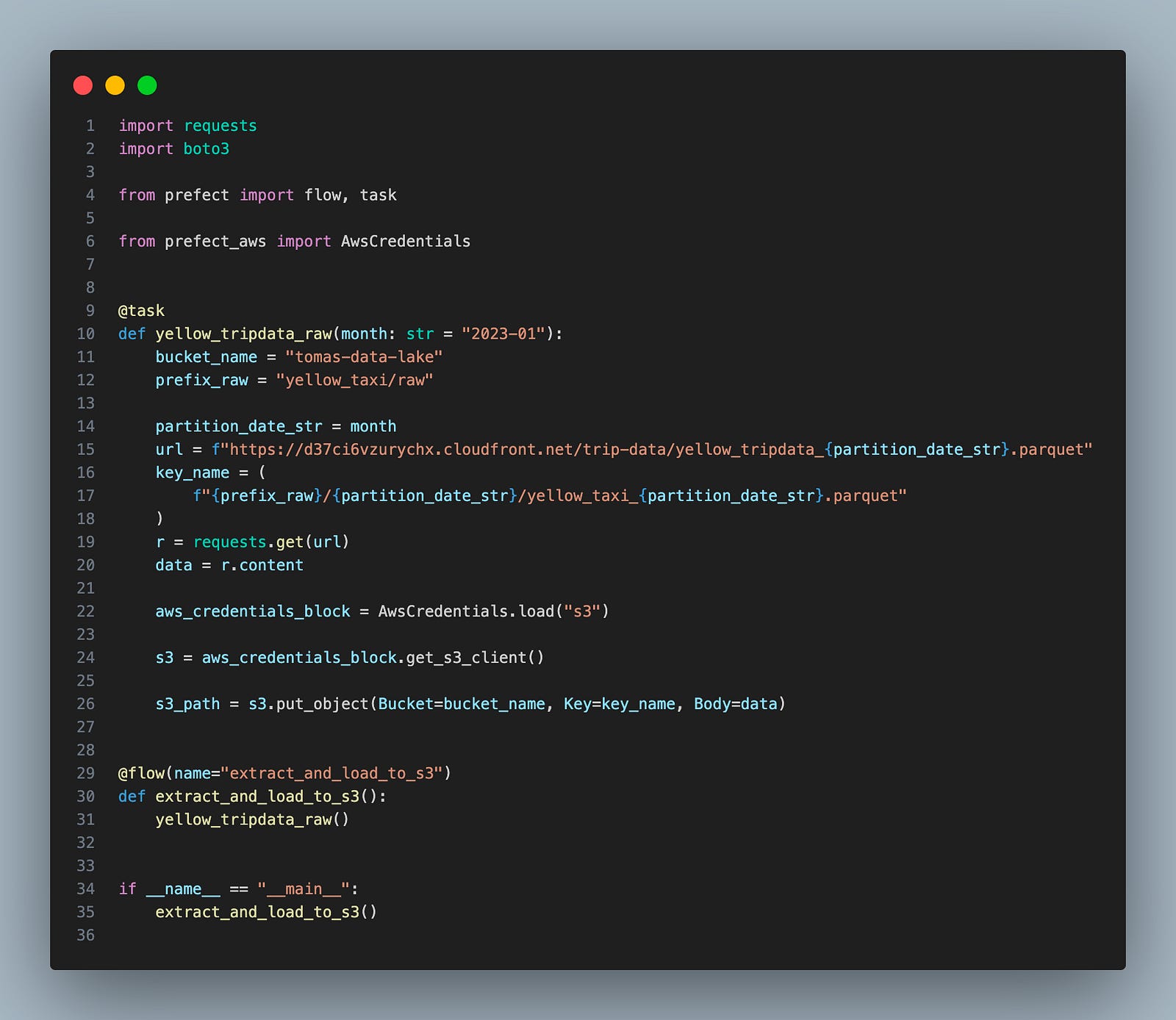

From start to finish, it took 9s to put the parquet file into S3. And code changes were quite minimal.
Now to look at the execution from UI, where it becomes more troubling. The thing is that Prefect creates a separate container, and if you’re used to server accessing objects easily, you’re in for a treat since now it’s not going to.
To share flows across Server and Agent, I’ve mounted the same directory via docker volumes ¯\_(ツ)_/¯
Now, the same code execution but from UI takes less time (~5s less). A couple of assumptions I have:
I’ve run the code from the Server container. UI and other Prefect components were taking resources, so naturally, Python had less to use.
UI is not considering new container spin-up time.

NOTE: Let’s talk about dbt and Prefect. As I understand duckdb part is not quite there yet; since installing from the requirements file prefect-dbt[duckdb] and prefect-dbt[cli], my dbt profiles.yml is invalid for the adapter. I assume that there are some dependency issues with Prefect and duckdb. To make comparisons reasonable, I did what I do best — hack around and create not sustainable solutions 😅. I’m not using those libraries, going the way of purists and installing dbt-core and dbt-duckdb.
In general, what added all components similar to dagster and code looks like:
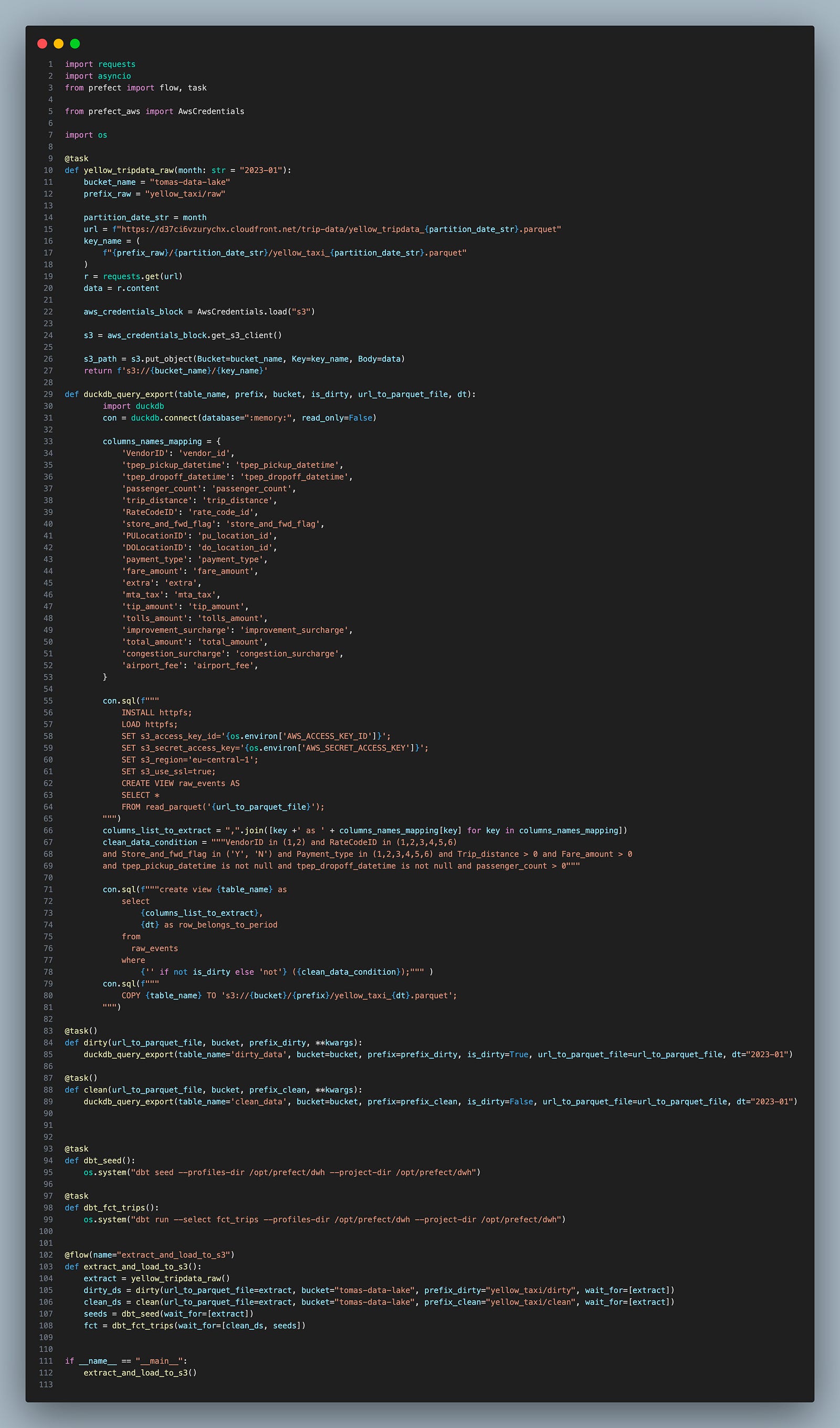
Looking at the whole flow in UI:
All things were executed sequentially! I tried to use prefect-dask and use
@flow(task_runner=DaskTaskRunner(), name="extract_and_load_to_s3")but for some reason, it didn’t help.
Backfilling
I haven’t seen an easy way to run a backfill. You can pass custom parameters with dates etc., and run separate runs.
To backfill, you could:
Create a separate flow that would take start and end date parameters, loop over the missing periods, and execute them.
Simple stupid approach by looping locally
Something I’ve missed in the docs
Kestra
I’ll start by saying that this orchestrator is purely YAML based. EVERYTHING is in YAML. This has pros and cons; some might be just purely because of my previous experiences. Nonetheless, let’s start with generic dates.
v0.4.0 was first released on Feb 22, 2022
No v1 yet
Kestra itself provides a more feature-rich Enterprise edition as a SaaS solution
Looking at community and other statistics:
Slack: 565 members
Github Stars: 3.6k
Downloads PyPi: 191 last month
Docker pulls: 31k
Architecture
Since I’m covering what can be covered with OSS, I’ll just put the image from Kestra on medium-size deployment here. There is one with Kafka and Elastic for Large enterprises, but

So it’s not fair to compare OSS features with Premium ones.
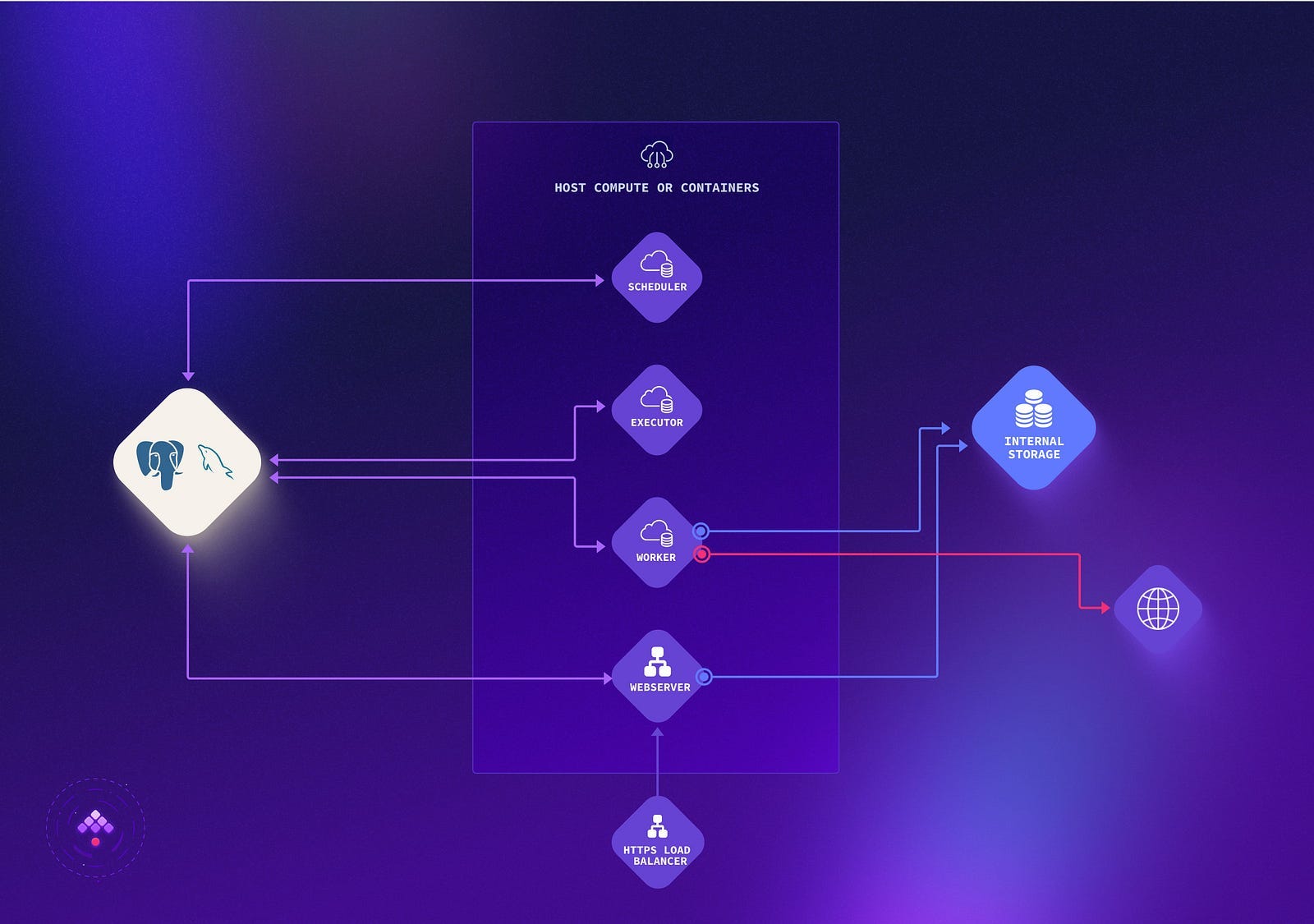
Orchestrator itself is purely Java written, with all of the plugins added for you immediately.
User interface

Ignore my 30% success rate since the snapshot starts when I just opened and scribbled some code to see how it looks and feels. But I already like Grafana’ish dashboard with successes, failures and generic metrics.
Blueprints is actually what I liked, and it helped me a lot. They provide many examples of its usage, which helps if you’re starting out, since syntax is a bit tricky. See it for yourself:
id: jsonFromAPItoMongoDB
namespace: blueprint
tasks:
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: generateJSON
type: io.kestra.plugin.scripts.python.Script
runner: DOCKER
docker:
image: ghcr.io/kestra-io/pydata:latest
script: |
import requests
import json
from kestra import Kestra
response = requests.get("https://api.github.com")
data = response.json()
with open("output.json", "w") as output_file:
json.dump(data, output_file)
Kestra.outputs({'data': data, 'status': response.status_code})
- id: jsonFiles
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- output.json
- id: loadToMongoDB
type: io.kestra.plugin.mongodb.Load
connection:
uri: mongodb://host.docker.internal:27017/
database: local
collection: github
from: "{{outputs.jsonFiles.uris['output.json']}}"I am not even talking where you can parallelize some flows. It reminded me of many pipelines I’ve written for BitBucket and Gitlab in previous experiences.
By the way, see the types as io.kestra.plugin.mongodb.Load, etc. I had a hunch it’s written in Java before I checked the repo 😅
Code
First thing first. All code you write is stored directly in DB (PostgreSQL or MySQL); it’s versioning too. So people who like to have their stuff in Git version control style — you’d have to do DB dumps or some other workarounds. By the way, I’ve taken some Prefect examples from Anna’s blogs or from her comments on other people's issues. She was DevRel at Prefect prior to Kestra. Give her a follow on her medium page.

Also, I ran into some issues with dynamic date parsing and then some issues with downloading the parquet file (memory issues). Running custom code also seems interesting. You must pass all code inside the yaml with a file name and a pipe. I assume it puts the text you provide into the file and then runs it.
After a couple of days trying it, bashing my head to make it work, I’m just going to leave it for now and might get back to it at some point in the future. It might be a premature assumption, but at least what I’m used to doing with orchestrators and Kestra is not there yet.
Summary
Let’s start with Prefect.
Has the second biggest community of my tested orchestrators.
Quickly was updated to v2, so it should be mature enough and feature-rich.
Changes from Airflow or Dagster code are minimal to make it work.
Blocks — credentials storing is very similar to Airflow.
Parallel running is quite complicated; at least following the instructions, I couldn’t make it run.
Deployments are complicated, with some overhead and multiple commands you have to run to make it work.
Backfills are complicated and only sometimes achievable. You’d need to do some custom coding to get it running.
Now let’s do Kestra:
See the appeal of YAMLs for less technical people
Still not mature enough for my use cases
It needs a lot of adjustments to move from other orchestrators
Code versioning sits in DB; to push it to Git or any version control system, you must extract it from DB.
Backfills also are not running
Dates parsing is complicated.
So in my eyes, my first picks, Airflow, Dagster and Mage, are way ahead of these two, even though Prefect seems to have quite a big community.